I Thought Virtual Threads Were Just Green Threads—They’re Actually Continuations on the Heap
I used virtual threads in an API earlier in this challenge. Spun up a few thousand threads, watched memory stay flat, called it a win. My mental model was simple: virtual threads are like Go’s goroutines—lightweight threads the runtime manages instead of the OS. Green threads. Done.
For thos who want to learn more about goroutines you can look into these videos to learn more about concurrency in go http://youtube.com/watch?v=5zXAHh5tJqQ
Then I tried to understand why a synchronized block could pin a virtual thread in Java 21 but not in Java 24.
Before that lets know what is pinnig a thread means. Pinning, the binding of a process or thread to a specific core, can improve the performance of your code by increasing the percentage of local memory accesses. But in java it is preventing a virtual thread from being unmounted from its carrier thread
That question pulled me into the underlying implementation, and I realized my mental model was completely wrong. Virtual threads aren’t just “lighter” OS threads. They’re heap-allocated continuation objects with their own stack chunks, scheduled by a work-stealing ForkJoinPool, with mount/unmount semantics
Here’s what I got wrong and what actually happens under the hood.
The Mental Model I Had (Wrong)
Before this deep dive, here’s what I thought:
- Virtual threads = JVM-managed lightweight threads (like goroutines)
- Main benefit = no 1MB stack reservation per thread
- They “just work” with existing blocking code
- Implementation details = “JVM magic” I didn’t need to understand
This model worked for basic usage. I could write Thread.ofVirtual().start(() -> ...) and handle thousands of concurrent requests without thinking about thread pools. Good enough.
But it didn’t explain the weird constraints I kept seeing:
- Why does
synchronizedpin threads in Java 21? - Why do people say “use ReentrantLock instead”?
- Why does the documentation warn about ThreadLocal with millions of threads?
- Why are stacks on the heap instead of… wherever stacks normally live?
The “green threads” model had no answers. Time to dig deeper.
What Virtual Threads Actually Are: Continuations
The core primitive isn’t a thread at all—it’s a continuation. This is the part that broke my mental model.
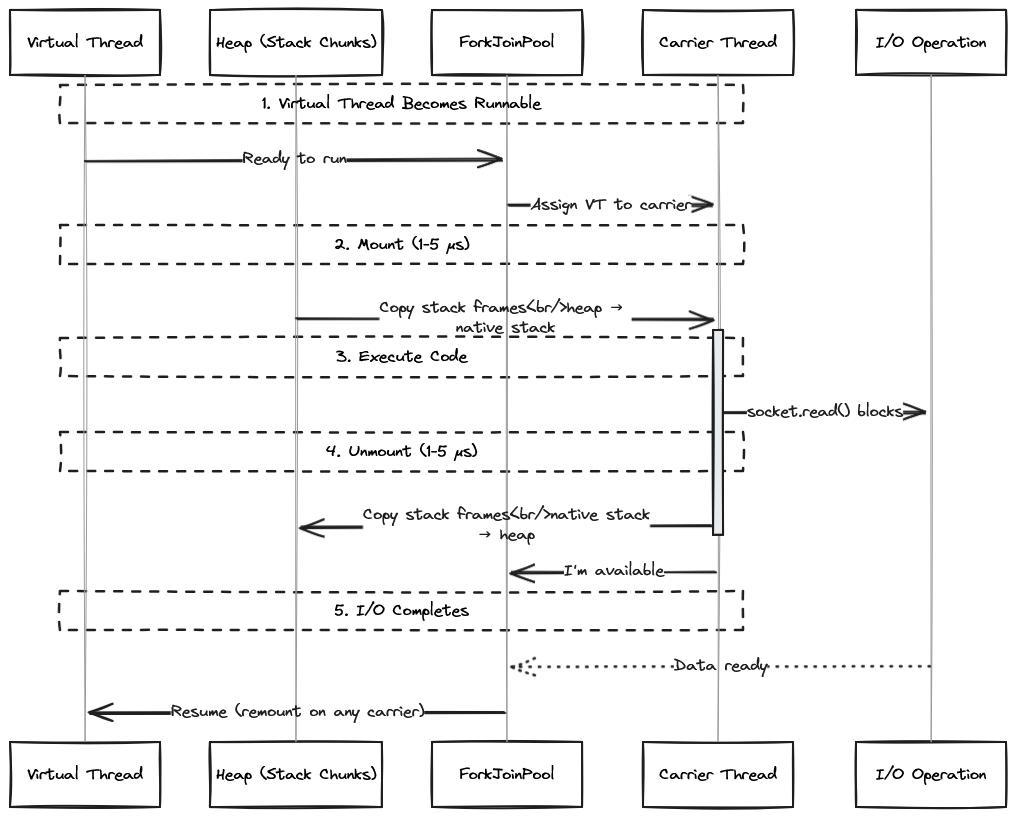
A continuation is a Java object that captures execution state: local variables, method call frames, the instruction pointer. When a virtual thread blocks on I/O, the JVM doesn’t let it block the underlying OS thread. Instead, the continuation object captures the current state, the virtual thread “unmounts” from its carrier thread, and the carrier becomes available for other virtual threads.
Here’s the internal API (not accessible to user code, but this is what happens):
| |
When socket.read() blocks, the continuation calls yield(scope). This doesn’t block the OS thread—it saves the execution state to the heap and returns control to the scheduler. Later, when the I/O completes, the scheduler picks an available carrier thread and resumes the continuation from where it left off.
This is not how platform threads work. Platform threads block the OS thread. The OS kernel handles the context switch. With virtual threads, the JVM handles everything in user space.
The Stack Problem: Why Heap Allocation Matters
Here’s the memory efficiency piece I thought I understood but didn’t.
Platform threads allocate their stacks in native OS memory—typically 1MB reserved at creation time, whether you use it or not. If you create 10,000 platform threads, you’ve reserved 10GB of native memory for stacks alone, even if most threads are blocked waiting for I/O with shallow call stacks.
Virtual threads store their stacks as stack chunk objects on the garbage-collected heap. These chunks grow dynamically based on actual call depth:
- Shallow I/O operation: ~1KB heap allocation
- Deep call chain: ~50KB heap allocation
- Deeply recursive algorithm: up to ~512KB (G1 GC region size limit)
The math changes dramatically:
- 10,000 platform threads: ~10GB native memory (reserved, not used)
- 10,000 virtual threads: ~10MB heap memory (actual usage)
But here’s the part I missed: this creates work during mount/unmount operations. When a virtual thread mounts on a carrier, the JVM copies stack frames from the heap to the carrier’s native stack. When it unmounts, frames copy back to the heap. This is fast (1-5 microseconds) but not free.
The trade-off: memory efficiency for CPU overhead during context switches. For I/O-bound workloads where threads spend most of their time blocked, this trade-off is massively in your favor. For CPU-bound workloads, you’re just burning cycles copying stacks around.
The Scheduler: ForkJoinPool in FIFO Mode
I assumed virtual threads had some custom scheduler. Nope—it’s a ForkJoinPool, the same work-stealing pool used by parallel streams, but configured differently.
Key differences from the common pool:
- FIFO mode instead of LIFO (better for long-running tasks)
- Default parallelism = number of CPU cores
- Dynamically expands when threads pin (more on this shortly)
The work-stealing algorithm means idle carrier threads steal virtual threads from busy carriers' queues. This keeps all carriers busy and improves utilization.
But here’s the critical constraint: virtual threads are cooperative, not preemptive. If a virtual thread runs CPU-bound code without calling any blocking operations, it monopolizes its carrier. No time-slicing. No forced context switch. This can starve other virtual threads.
I’ve always had preemptive thread scheduling. Virtual threads don’t work that way. If you have a CPU-bound task, use a platform thread or parallel stream. Virtual threads are for I/O-bound concurrency.
The Pinning Problem (And Why Java 24 Matters)
This is where my “green threads” model completely fell apart.
In Java 21-23, if a virtual thread blocks inside a synchronized block, it pins to its carrier thread. The virtual thread cannot unmount. The carrier thread blocks. You’ve just turned your virtual thread back into a platform thread, defeating the entire purpose.
Why? Because synchronized monitors are tied to the OS thread identity. The JVM couldn’t separate the monitor state from the carrier thread. If the virtual thread unmounted, the monitor would be released incorrectly.
This is a massive problem if you’re working with legacy code full of synchronized blocks. Your virtual threads pin constantly, the scheduler compensates by expanding the carrier pool beyond the CPU count, and you end up with hundreds of OS threads anyway.
The workaround in Java 21: replace synchronized with ReentrantLock, which properly unmounts virtual threads. But that’s a non-trivial refactor if you have thousands of synchronized methods.
Java 24 (JEP 491) fixes this. Virtual threads can now hold monitors independently of their carriers. When a virtual thread blocks inside synchronized code, it unmounts normally. The monitor state is tracked by the JVM, not the carrier thread. When the lock is acquired, the virtual thread resumes on any available carrier.
This was the implementation detail that made me realize how sophisticated this system is. The JVM had to fundamentally change how monitors work to make virtual threads scale with real-world Java code.
What I Measured (And What Surprised Me)
I wanted to see the memory difference myself, so I wrote a simple test:
| |
The platform thread version queues 9,800 tasks because only 200 threads exist. The virtual thread version runs all 10,000 concurrently because creating threads is cheap.
What surprised me: CPU utilization with virtual threads was higher (85% vs 60%) on an I/O-bound workload. The platform thread pool left cores idle waiting for threads to unblock. Virtual threads kept carriers busy by unmounting blocked threads and scheduling runnable ones.
The Trade-offs I Didn’t Expect
Virtual threads are not always better. Here’s what I learned:
Use virtual threads when:
- I/O-bound workloads (network calls, database queries, file I/O)
- You need millions of concurrent operations
- Blocking code is simpler than async pipelines
- You’re on Java 24+ (or can avoid
synchronized)
Use platform threads when:
- CPU-bound workloads (no blocking = no benefit from unmounting)
- You need thread priorities or custom scheduling
- You’re calling native code frequently (FFM/JNI pins threads)
- You have deeply recursive algorithms (stack size limits)
The ThreadLocal trap: If you use ThreadLocal variables with millions of virtual threads, you’re allocating millions of ThreadLocal entries on the heap. This can create memory pressure. Java 21 introduced Scoped Values as a better alternative for virtual thread scenarios—lexically scoped, no per-thread allocation.
The debugging challenge: Thread dumps with millions of virtual threads are… interesting. The new JSON format helps, but tooling is still catching up. Structured concurrency (preview feature) helps by establishing task hierarchies debuggers can visualize.
What I’ll Do Differently
Before this deep dive, I treated virtual threads as a drop-in replacement for thread pools. Now I know better.
For new I/O-bound services: Virtual threads by default. The simplicity of thread-per-request code with the scalability of async systems is worth it.
For existing services: Check for synchronized blocks first. If we’re on Java 24+, virtual threads are safe. If we’re stuck on Java 21-23, I need to profile for pinning (-Djdk.tracePinnedThreads=full) and decide if the refactor to ReentrantLock is worth it.
For CPU-bound tasks: Stick with platform threads or parallel streams. Virtual threads add overhead without benefit.
For mixed workloads: Separate pools. Virtual threads for I/O, platform threads for CPU work. Don’t mix them in the same executor.
The mental model shift matters. Virtual threads aren’t just “lighter threads”—they’re a different concurrency model with different trade-offs. Understanding continuations, heap-based stacks, and the mount/unmount mechanism helps me make better architectural decisions.
Next time I see a service hitting thread pool limits, I’ll know exactly why virtual threads might help—and when they won’t.
References
Technical details verified against:
- JEP 444: Virtual Threads
- JEP 491: Synchronize Virtual Threads Without Pinning
- Foojay: Continuations Foundation of Virtual Threads
- Oracle Java Magazine: Virtual Threads Design
- nipafx: Virtual Thread Deep Dive
- InfoQ: Virtual Threads Lightweight Concurrency
- Cashfree: Production Lessons from Virtual Threads
- YCrash: Virtual Threads vs Platform Threads Study
- Stackademic: Spring Boot Virtual Threads Benchmarking
- Academic Study: Virtual Threads Performance Analysis