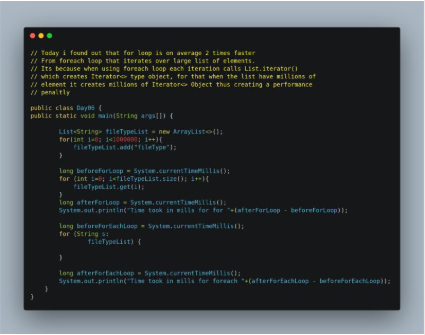
Update, May 2026: the original benchmark below should not be treated as evidence that a classic
forloop is meaningfully faster thanforeach. It usedSystem.currentTimeMillis(), no warmup, no repeated forks, and loops whose work could be optimized away. A proper Java microbenchmark should use JMH and should consume real work so the JIT cannot remove the measurement target.
This post is kept as a learning snapshot, but the conclusion has changed: prefer the loop that makes the code clearer unless a production measurement with representative data shows otherwise.
Transcribed from the original LinkedIn image post.
| |
What a better benchmark needs
A useful version of this test needs:
- JMH warmup and measurement iterations.
- Several forks so one JVM run does not dominate the result.
- Real work inside each loop.
- A consumed result so the JIT cannot remove the loop.
- Representative data structures, because arrays,
ArrayList,LinkedList, and custom collections do not behave the same way.
For this series, Day 69 covers JMH in more detail: Day 69 - Unlocking Java Performance Secrets.
The original LinkedIn graphic is preserved below.